Konzept
Um das hier genutzte System zu verstehen, muss man sich zunächst überlegen, wie man naiv Daten aus Webseiten extrahieren könnte. Nehmen wir als Beispiel eine einfache Webseite, die nur Daten zu einem Film enthällt.
<html>
<body>
<h1>Mission Impossible</h1>
<h2>1996 - PG-13 - 1h 50m</h2>
<h3>
An American agent, under false suspicion of disloyalty, must discover and
expose the real spy without the help of his organization.
</h3>
<div id="actors">
<div class="actor">
<a href="https://filminfos.de/actor/a32342">Link</a>
<h2>Tom Cruise</h2>
<h3>Ethan Hunt</h3>
</div>
<div class="actor">
<a href="https://filminfos.de/actor/a714241">Link</a>
<h2>Jon Voight</h2>
<h3>Jim Phelps</h3>
</div>
</div>
</body>
</html>
Wir könnten nun einfach für jedem Wert, den wir extrahieren wollen, einen XPath zuweisen, also z.B.
Title: descendant::h1
ActorNames: descendant::div[@class='actors']/descendant::h3
ActorUrl: descendant::div[@class='actors']/descendant::a
ActorRoles: descendant::div[@class='actors']/descendant::h3
Die Werte zu extrahieren funktioniert damit problemlos:
Title: ["Mission Impossible"]
ActorNames: ["Tom Cruise", "Jon Voight"]
ActorRoles: ["Ethan Hunt", "Jim Phelps"]
ActorUrls:
["https://filminfos.de/actor/a32342", "https://filminfos.de/actor/a714241"]
Dank spezieller Array Datentypen in Datenbanken wie Postgres, könnten wir die Daten auch direkt in eine Datenbank einfügen.
Später können wir dann ggf. manuell zuordnen was zu was gehört, anhand der Position innerhalb der arrays.
Wir verlassen uns dabei allerdings darauf, dass dass unsere erste extrahierte Actor URL auch zu dem ersten Namen und der ersten Rolle gehört.
Schauen wir uns allerdings dieses Beispiel an
Title: "Mission Impossible"
ActorNames: ["Tom Cruise", "Jon Voight"]
ActorRoles: ["Ethan Hunt"]
ActorUrls:
["https://filminfos.de/actor/a32342", "https://filminfos.de/actor/a714241"]
so sehene wir, dass wir in diesem Fall nicht mehr zuordnen können welche Rolle zu welchem Actor gehört. Noch schlimmer sieht es hier aus:
Title: "Mission Impossible"
ActorNames: ["", "Tom Cruise", "Jon Voight"]
ActorRoles:
[
"Ethan Hunt",
"<a href='http://temu.com'>Buy TOP Chinese Toy Planes NOW!! <a>",
"Jim Phelps",
]
ActorUrls:
[
"https://filminfos.de/actor/a32342",
"https://google.com",
"https://filminfos.de/actor/a714241",
]
Hier haben wir die selbe Anzahl an Ergebnissen aber es ist ersichtlich, dass eine einfache positionelle Zuordnung trotzdem nicht möglich ist.
Dies ist nicht nur ein theoretisches Problem. Das Fehlen von Daten kann durchaus beabsichtigt sein, XPaths können zu schlecht sein und Seiten verändern sich ständig. Was wir brauchen ist ein besseres System, um diese Daten zu zu ordnen:
Nodes
Schauen wir uns die Beispiel Seite noch einmal an so sehen wir, dass es bestimmten Bereich gibt, die zu underschiedlichen Dingen gehören.
<!-- Movie Start -->
<html>
<body>
<h2>1996 - PG-13 - 1h 50m</h2>
<h3>
An American agent, under false suspicion of disloyalty, must discover and
expose the real spy without the help of his organization.
</h3>
<div id="actors">
<!-- Actor 1 Start -->
<div class="actor">
<a href="https://filminfos.de/actor/a32342">Link</a>
<h2>Tom Cruise</h2>
<h3>Ethan Hunt</h3>
</div>
<!-- Actor 1 End -->
<!-- Actor 2 Start -->
<div class="actor">
<a href="https://filminfos.de/actor/a714241">Link</a>
<h2>Jon Voight</h2>
<h3>Jim Phelps</h3>
</div>
<!-- Actor 2 End -->
</div>
</body>
</html>
<!-- Movie End -->
Da der Begriff "Bereiche" etwas ungenau definiert ist, nehmen wir statdessen den
HTML Begriff Nodes, der immer genau den Bereich zwischen: <></> Klammern
bezeichnet. In diesem Fall wäre der erste Actor Node also:
<div class="actor">
<a href="https://filminfos.de/actor/a32342">Link</a>
<h2>Tom Cruise</h2>
<h3>Ethan Hunt</h3>
</div>
Da wir nun mit HTML Nodes arbeiten, können wir auch einfach Xpaths finden, um diese zu selektieren und relativ zu diesen dann die wirklichen Daten extrahieren.
Natürlich ist dies nur ein minimal-Beispiel, doch in der Praxis sind Nodes oft wirklich nicht viel größer, als hier gezeigt. Da wir nur noch einen Bruchteil der Seite betrachten, wird sowohl die Xpath Generierung, als auch die Extrahierung und Zuordnung trivial. Alle Daten, die wir extrahieren gehören immer genau zu dem Node, zu dem sie relativ ausgewertet wurden.
Um Verwechslungen zu vermeiden, wird bei diese Xpaths nun angegeben zu welchem Node diese relativ sind. Unsern relativen Xpaths sind nun also:
Movie.Title: descendant::h1
Movie.Actor: descendant::div[@class='actor']
Actor.Name: child::h3
Actor.Url: child::a
Actor.Role: child::h3
Und bilden damit folgende Struktur ab:
[Movie]
|
+------+--------+
| |
Title [Actor]
|
+----------+-----------+
| | |
Url Name Role
Es sollte ebenfalls verständlich sein, dass wir beim Extrahieren der Daten immer ganz Oben anfangen müssen und uns nach unten vorarbeiten müssen, um sicher zu sein, dass der Node zu dem man relativ ist bereits ausgewertet wurde.
Wer mit Baumdiagrammen und der Unterscheidung zwischen Leafs und Nodes vertraut ist, dem fällt auf, dass unsere Nodes auch im Baumdiagramm die Nodes sind. Die Leafs, oder auf deutsch Blätter in diesem Diagramm sind die wirklichen Daten, die wir Extrahieren. Um zwischen diesen beiden Arten zu Unterscheiden, nennen wir die Blätter nun "Data Points", da nur diese wirklich Daten extrahieren.
Wenn wir diese Methode nutzen, um die Daten zu extrahieren, erhalten wir folgende Daten:
{
"Movie": [
{
"Title": "Mission Impossible",
"Actor": [
{
"Name": "Tom Cruise",
"Role": "Ethan Hunt",
"Url": "https://filminfos.de/actor/a32342"
},
{
"Name": "Jon Voight",
"Role": "Jim Phelps",
"Url": "https://filminfos.de/actor/a714241"
}
]
}
]
}
Es sollte ersichtlich sein, dass das Fehlen von z.B. einer Rolle hier klar zugeordnet werden kann und dass zusätzliche Werte nur innerhalb eines Nodes zu falschen Ergebnissen führen können, nichtaber über diese hinaus.
Idents
Das einzige verbleibende Problem ist die Zuordnung dieser Ergebnisse in eine Datenbank. Wenn wir überlegen, wie eine passende Datenbank aussieht, könnten wir uns folgendes Schema überlegen:
+---------------+ +------------------+ +--------------+
| Movie | | Actor2Movie | | Actor |
+---------------+ +------------------+ +--------------+
| PK: id |<------| PK,FK1: movie_id | /-->| PK: id |
| UNIQUE: url | | PK,FK2: actor_id |--/ | UNIQUE: url |
| title | | role | | name |
+---------------+ +------------------+ +--------------+
Wir können dieses Schema auch auf eine etwas untypischere Art visualisieren:
[Movie(PK: id, uniq: url)] <------------------------+
| |
+------+--------+ |
| | | |
title url [Actor(PK: id, uniq: url)] <--- [Actor2Movie]
| |
+----------+ |
| | |
url name role
Im Vergleich zu unserer Node/Points definition von zuvor erkennt man, dass wir Nodes Tabellen zuordnen können und die Punkte in den meisten Fällen direkt den Spalten der Tabelle. Mit diesem Mapping im Kopf, können wir auch einmal durchgehen, wie das wirkliche Einfügen der zuvor extrahierten Daten abläuft. Dieser Prozess besteht immer grob aus folgenden Schritten:
- Starte beim obersten Knoten (dem root node)
- Wenn unser node eine assoziierte Tabelle hat
- Finde oder füge eine neue Zeile in die Tabelle ein, die dem einem einmaligen Mapping entspricht
- Dieses einmalige Mapping besteht aus extrahierten Punkte, und/oder die oder der aktuelle URL zu Spalten in der DB
- Dieses Mappings nennen wir Idents
- Finde oder füge eine neue Zeile in die Tabelle ein, die dem einem einmaligen Mapping entspricht
- Wenn unser node eine assoziierte Many To Many Tabelle hat
- Finde oder füge eine neue Zeile in die Many To Many Tabelle ein
- Nutze dafür die zuvor gefundene Zeile unserer Tabelle und die id unseres parent Nodes
- Finde oder füge eine neue Zeile in die Many To Many Tabelle ein
- Gehe alle unsere points durch und füge diese entweder in unsere, oder die Many To Many Tabelle ein
- Für alle Nodes, die direkt unter unserem node sind, beginne erneut bei Schritt 2
Da wir als input natürlich kein Diagramm haben, nehmen wir eine Konfiguration wie diese, die praktisch das selbe wie das Diagramm oben über Nodes & Points aussagt:
Movie:
table: Movie
idents:
- url: CURRENT_PAGE_URL
points:
- title: "insert node table"
children_nodes:
Actor:
table: Actor
mtm_table: Actor2Movie
idents:
- url: point-url
points:
- url: "handled in idents"
- name: "insert node table"
- role: "insert node mtm table"
1. Beginne beim Movie Node
2. Ident definiert dass unsere aktuelle URL zu der url Spalte gehört
Keine Zeile mit unserer url in der Datenbank gefunden
Füge neue Spalte ein => movie_id = 1
3. Wir haben keine MtM tabelle
4. Füge Title in die title Spalte ein
5. Beginne erneut bei 2. mit Actor 1 & Actor 2
===>
2. Ident definiert dass unser url point zur url Spalte in der DB gehört
Keine Zeile mit der url in der Datenbank gefunden
Füge neue Spalte ein => actor_id = 1
3. Wir haben eine many2many tabelle. Wir haben actor_id = 1, movie_id = 1
Keine Zeile mit den Werten in der Datenbank gefunden
Füge neue Spalte ein => actor_to_movie_id = 1
4. Füge Name in die name Spalte ein
Füge Role in die role Spalte der mtm ein
<===
===>
2. Ident definiert dass unser url point zur url Spalte in der DB gehört
Keine Zeile mit der url in der Datenbank gefunden
Füge neue Spalte ein => actor_id = 2
3. Wir haben eine many2many tabelle. Wir haben actor_id = 2, movie_id = 1
Keine Zeile mit den Werten in der Datenbank gefunden
Füge neue Spalte ein => actor_to_movie_id = 2
4. Füge Name in die name Spalte ein
Füge Role in die role Spalte der mtm ein
<===
Automatisierung
Das ganze wirkt auf den ersten Blick ggf. sehr komplex (und das kann es auch sein). Es bietet allerdings auch viele Möglichkeiten Prozesse zu vereinfachen.
Um Xpaths zu generieren müssen wir die HTML Seite ohnehin annotieren und diesen Annotationen sinnvolle namen geben. Was also, wenn wir den Prozess ähnlich durchgehen, wie die Extraktion, also von oben nach unten. Wir nennen unsere annotation movie und wählen einfach mit einem Klick die ganze Seite aus.
<body webdb='Movie'>
...
Sofern wir voneinem engen Annotation=>Node=>Table mapping ausgehen, können wir ohne weiters zu tun bereits den erforderlichen Node und die Tabelle erstellen.
Das gleiche wiederholen wir mit dem Actor.
<body webdb='Movie'>
...
<div class="actor" webdb="actor">
...
</div>
...
<div class="actor" webdb="actor">
...
</div>
...
Da dieser nun innerhalb des HTML nodes des Movies ist wissen wir, dass auch der Actor node unterhalb des Movie nodes sein muss. Damit kenenn wir auch die Tabellen Relationen und können eine MtM Tabelle erstellen.
Markieren wir nun die Punkte, müssen wir lediglich angeben, ob diese in die jeweilige MtM, oder die normale tabelle geschrieben werden müssen. Die assoziation zu points lässt sich daraus ableiten was der erste annotierte HTML Knoten ist, der darüber liegt.
<div class="actor" webdb="actor"> <<<<<<<<<<<<<<<<<<<<+ name muss zu actor gehören
<a href="https://filminfos.de/actor/a32342">Link</a> |
<h2 webdb="name">Tom Cruise</h2> >>>>>>>>>>>>>>>>>>>+
<h3>Ethan Hunt</h3>
</div>
Mit diesem Verfahren lassen sich Punkte und zugehörige Tabellen Spalten nach kurzer Annotation der Nodes also eigens durch einen Namen und das Klicken auf das Element definieren.
Zudem können wir auch Seiten übergreifend agieren. Angenommen wir wollen auf der Such-Seite die URL der gefundenen filme extrahieren, oder auf der Movie Seite die Actors beim Crawlen verfolgen. Wir können einfach auswählen, dass wir einen wichtigen Link annotieren. Sobald wir den Punkt ausgewählt haben, können wir:
- Direkt den richtigen Node finden
- Einen Eintrag für die URL zur Tabelle des Nodes hinzufügen
- Den Link als Ident zum Node hinzufügen
- Den Link als beim crawling weiter zu verfolgendend definieren
- Eine neue leere Seiten Definition erstellen
- Einen obersten Knoten auf dieser Seite erstellen, der die page url nimmt und als ident für die gerade erstellte Spalte festlegt
Die einzigen Schritte, die ein Nutzer wirklich noch machen muss sind:
- Namen vergeben
- Auswählen, ob mehrere Elemente Annotiert werden sollen
- Zwischen Node & Point unterscheiden
- Element(e) auswählen
Im folgenden wird nun erklärt, wie die Software wirklich praktisch zu benutzen ist
Installation
Die WebDB Chrome Erweiterung lässt sich auf webdb.click herunterladen. Alternativ auch hier als direkter link.
Die heruntergeladene Datei ist ein Zip-Archiv, das bedeutet sie muss erst entpackt werden, bevor sie verwendet werden kann. Ich denke dieser Schritt sollte ohne weitere Erklärung machbar sein.
Daraufhin sollte es einen neuen Ordner geben, in dem sich der Code für die Erweiterung befindet.
Um diese Erweiterung zu laden, muss die Erweiterungs-Seite in Chrome geöffnet werden. Dazu:
- Oben rechtes, auf die drei Punkte klicken
- Erweiterungen
- Erweiterungen Verwalten
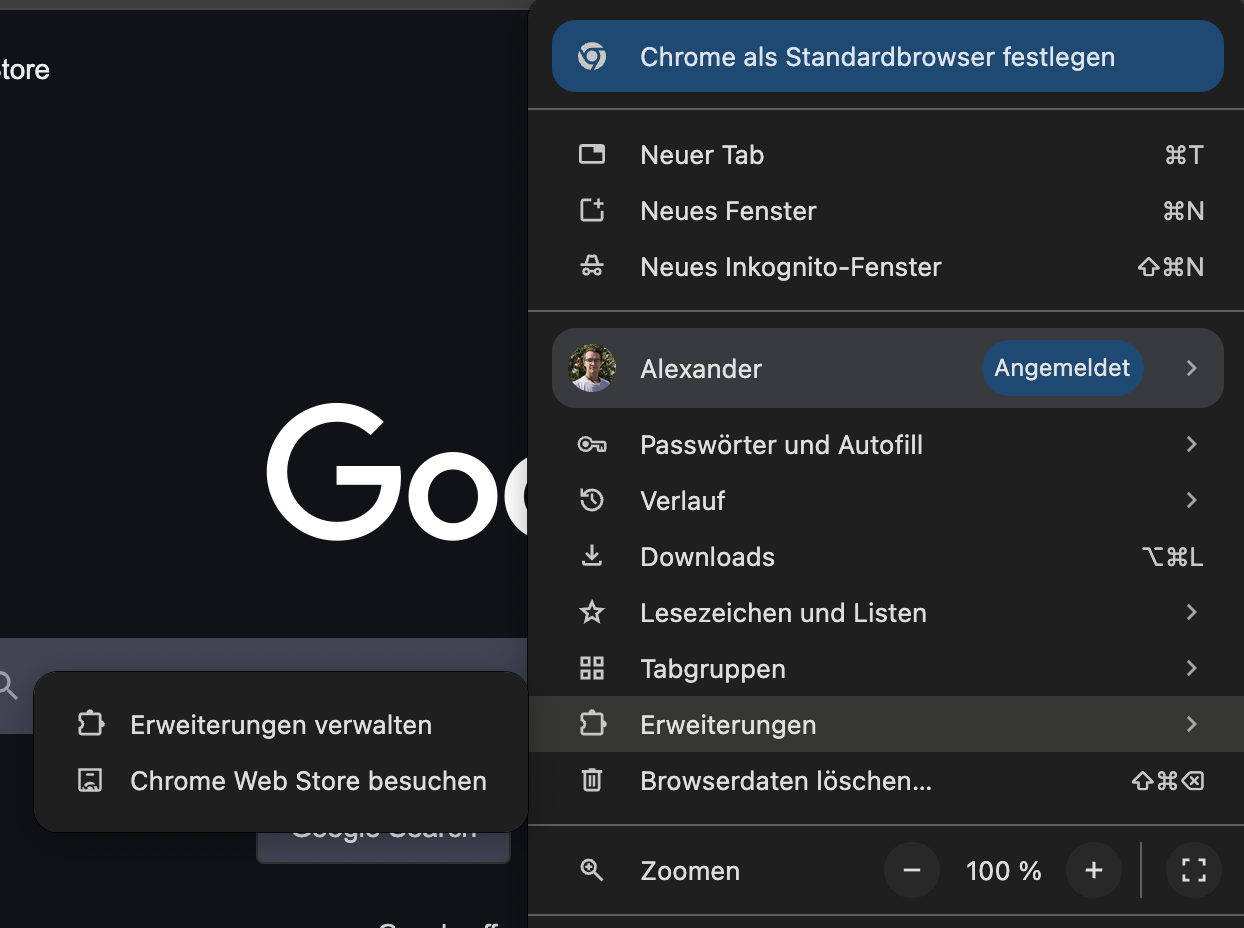
Dies öffnet die interne chrome://extensions/ Seite. Dort oben rechts den Entwicklermodus
aktivieren, um die Erweiterung laden zu können. Danach nun auf den "Entpackte
Erweiterung laden"-Knopf oben link klicken und in dem neu geöffneten Fenster
nun den zuvor entpackten Ordner auswählen.
Das ganze sollte nun etwa so aussehen:
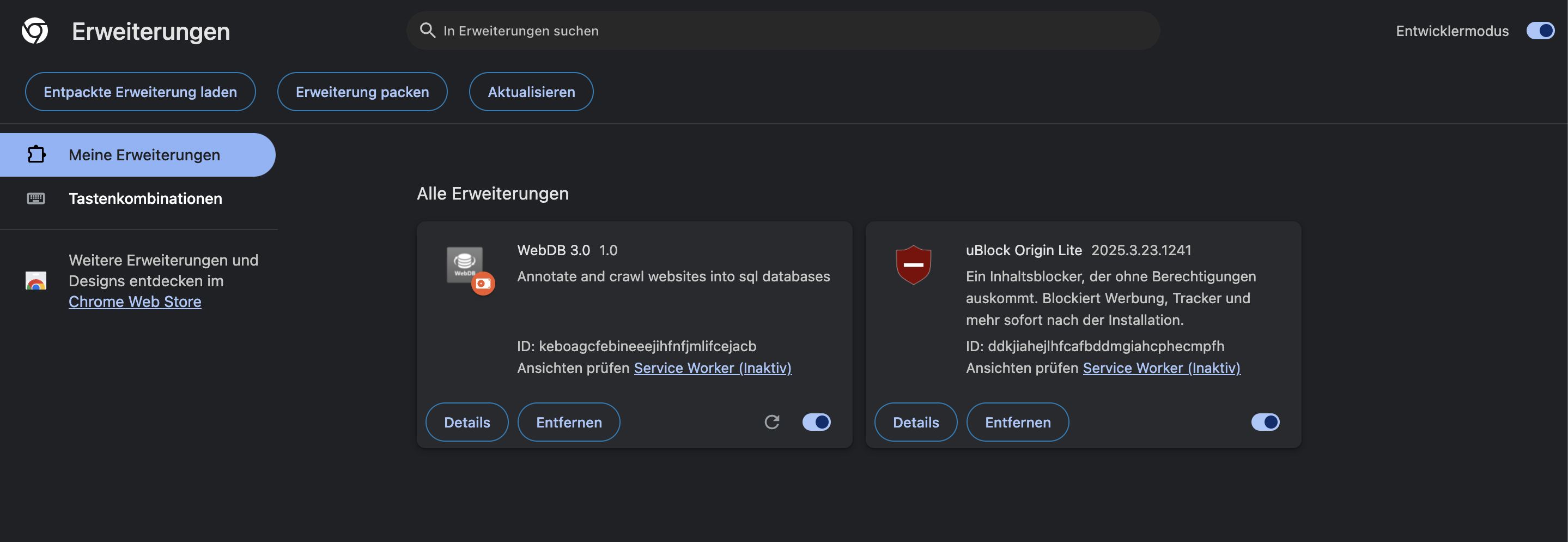
Für eine einfachere Nutzung, empfehle ich die Erweiterung zu "Pinnen". Dazu auf das Puzzle Symbol oben rechts klicken und den Pin neben "WebDB 3.0" anklicken. Daraufhin befindet sich das WebDB icon fest oben in der Navigations-Leiste.
Login
Öffnet man die Erweiterung nun durch ein klick auf das Icon in der Navigations-Leiste, öffnet sich ein Fenster zum Login.
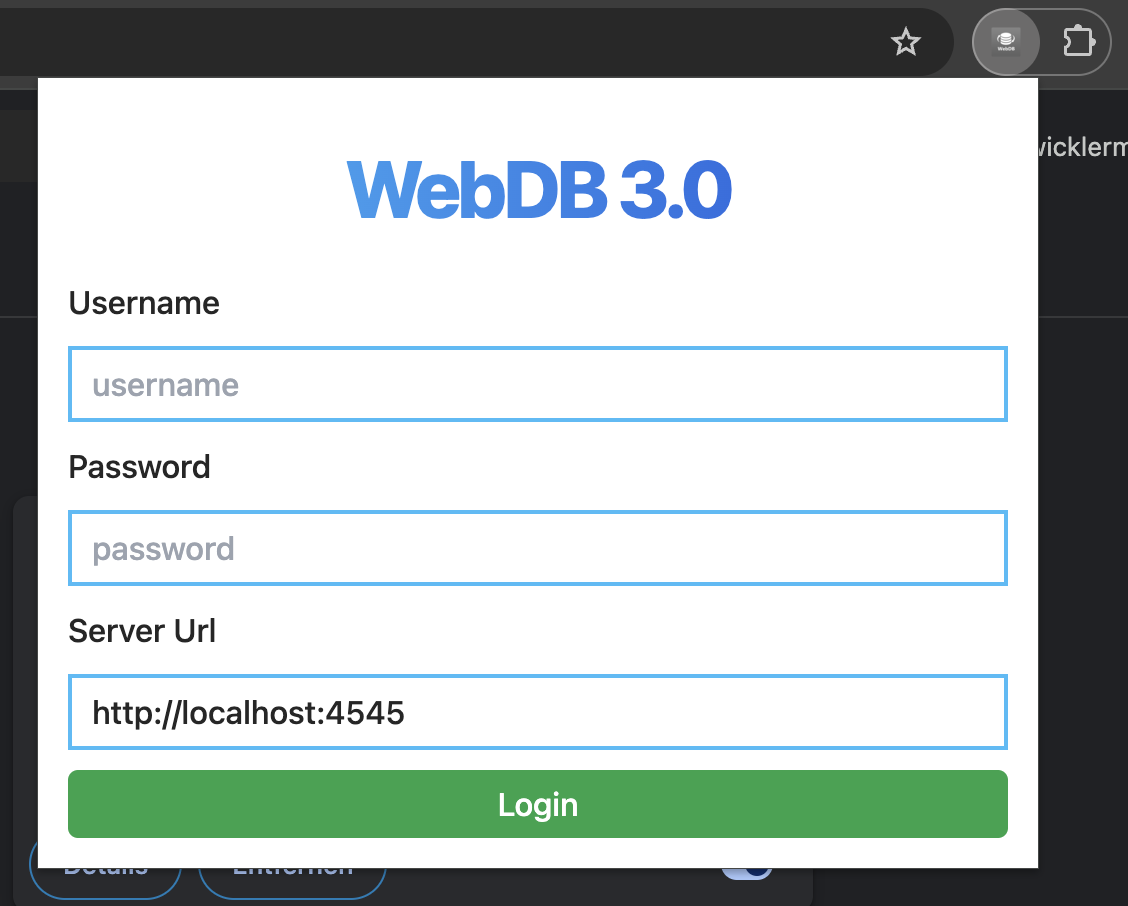
Die Nutzung von WebDB benötigt einen Account. Diese werden aktuell nur manuell generiert und sollten dem Leser bereits bekannt sein. Falls nicht, schreibt mir einfach eine Mail an webdb@marenga.dev
Wichtig, aktuell ist die Server Url noch eine lokale zum testen. Diese muss durch
https://webdb.click
ersetzt werden.
Danach einfach auf "Login" klicken. Sofern Username & Passwort korrekt waren, öffnet sich nun ein neues interface.
Projekt Konfiguration
Um später mehrere Webseiten korrekt in die selbe Datenbank schreiben zu lassen, benötigt es eine kurze Konfiguration dazu was gecrawlt werden soll.

Allgemein gilt dabei, dass im rechten Textfeld ein Name eingegeben wird und mittels klick auf "+" ein neues Element in diesem Bereich hinzugefügt wird.
Wichtig dabei, alle Namen, bzw. Identifier müssten gewissen Anforderungen erfüllen, um z.B. als Annotation, oder Text in der DB keine Probleme zu machen.
Diese Anforderungen sind:
- Der Name darf nur ASCII-alphanumerische Zeichen oder Unterstriche enthalten.
- Der Name muss mit einem alphabetischen Zeichen beginnen.
- Die Länge des Namens muss mehr als 2 Zeichen und weniger als 50 Zeichen betragen.
- Der Name darf nicht mit "_id" oder "_time" enden
Project
Ein Projekt bündelt mehrere Webseiten in einer Datenbank. Es sollte nach dem benannt werden was man crawlt und nicht wo. Das bedeutet wenn man vorhat IMDB und Rottentomatos zu crawlen, könnte man sie in einem Movie, oder Cinema Projekt bündeln.
Site
Diese ist der name der wirklichen Webseite, also z.B. IMDB. Der Name ist nicht gezwungener maßen die Domain einer URL, es macht allerdings die Organisation einfacher. Dies ist auch das Level, auf dem man das Crawling startet. Das bedeutet man würde nicht ein ganzes Projekt (Movies => IMDB & Rottentomatos) zusammen crawlen und auch nicht nur eine Unterseite (Top 250 Movies), sondern konfigurieren wie und welche Unterseiten eine Webseite hat und dann alle Start-Seiten crawlen. Dies ermöglicht es auch "rekursiv" zu crawlen, also Unterseiten zu haben, die auf neue Unterseiten zum crawlen verweisen.
Page
Diese ist eine konkrete Unterseite, also z.B. Top_250_Movies, oder Technical_Details. Auf diesem Level werden Annotationen und Xpaths daraus XPaths generiert, da wir hier die wirklich Daten extrahieren wollen und sich unterschiedliche URLs einer Unterseite nicht groß voneinander unterscheiden sollten.
Mit Project>Site>Page sinnvoll erstellt, kann nun die Annotation und Konfiguration der Seite gestartet werden, dazu einfach auf die gewünschte Seite navigieren und den "Start Annotation" Knopf drücken.
Seiten Konfiguration
Das Interface, um eine Seite zu konfigurieren, ist ein Fenster, das über der Seite angezeigt wird.
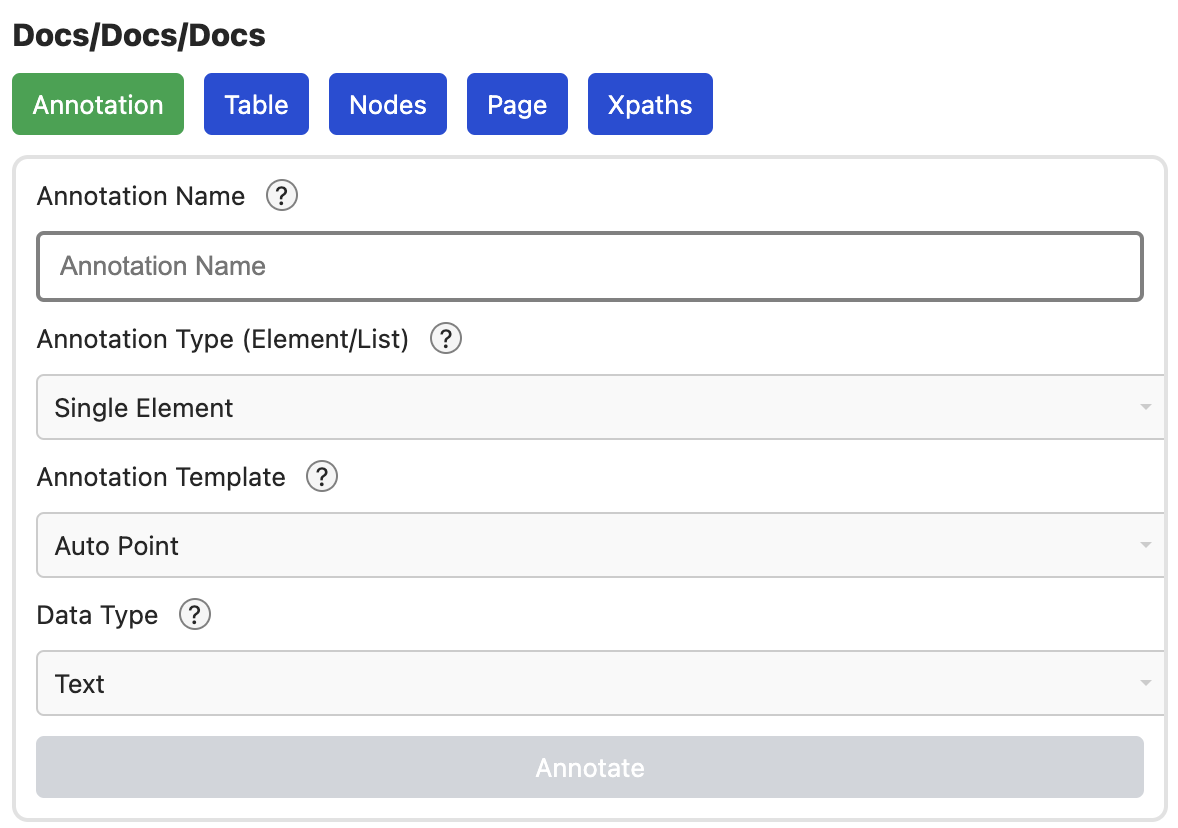
Darin gibt es 5 Tabs, um verschiedene Aspekte zu konfigurieren. Zum besten Verständnis, empfehle ich diese Reihenfolge:
Für eine kurze Quickstart Anleitung zum simplen crawling, sollte ein kurzer Überblick zum Annotieren genügen. Danach, kann direkt das Beispiel angeschaut werden.
Tabellen Konfiguration
Im Table tab, lassen sich die Tabellen der Datenbank konfigurieren.
Neue Tabelle
Ein klick auf New Table öffnet den Dialog zum Erstellen einer neuen Tabelle.
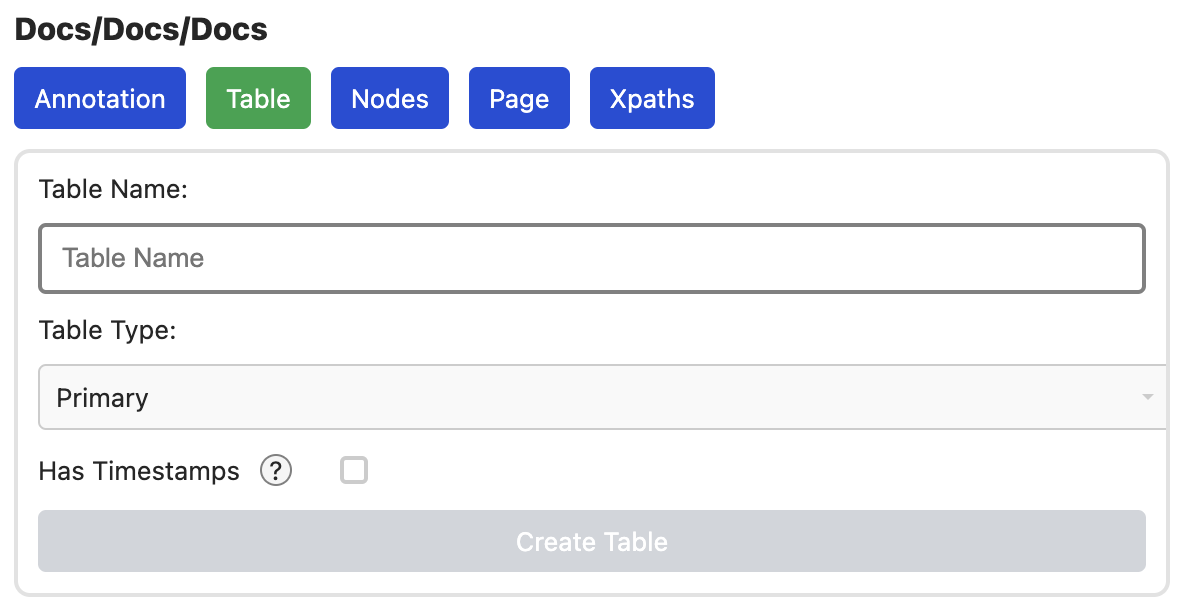
Darin lässt sich der Typ der Tabelle bestimmen
- Primary: Eine normale Tabelle, in die Daten geschrieben werden können und die andere Tabellen Typen referenzieren können
- Secondary: Eine Tabelle mit einer
One-To-OneRelation zu einer anderen Primary Table. Damit lassen sich Tabellen schmaler machen, also z.B. nur wichtige Daten, wieURL, Titlein eine Primary table zu schreiben und alles andereDescription, UserRatingin eine, oder mehrere andere Tabellen zu schreiben. Ich bin selbst nicht überzeugt von dieser Nutzung, aber WebDB 2.0 hatte dieses Feature, also gibt es das hier auch. - Many To Many: Eine Tabelle, die zwei andere Tabellen miteinander
verbindet. Nach Konvention, sollte man diese nach dem Schema
TableA2TableBbenennen. Diese Tabelle kann auch extra Felder haben, um z.B. den speziellen Typ der Relation anzugeben (Actor) und/oder andere extra Infos, wie die Rolle in einem Film (Darth Vader).
Zudem gibt es eine Option für Timestamps. Diese speichert die Zeit der Erstellung und die Zeit des letzten Updates für jede Zeile.
Create Table erstellt die Tabelle
Neue Spalte
Mit einer vorhandenen Tabelle, zeigt sich eine neue Option, um für jede Tabelle neue Spalten hinzuzufügen.
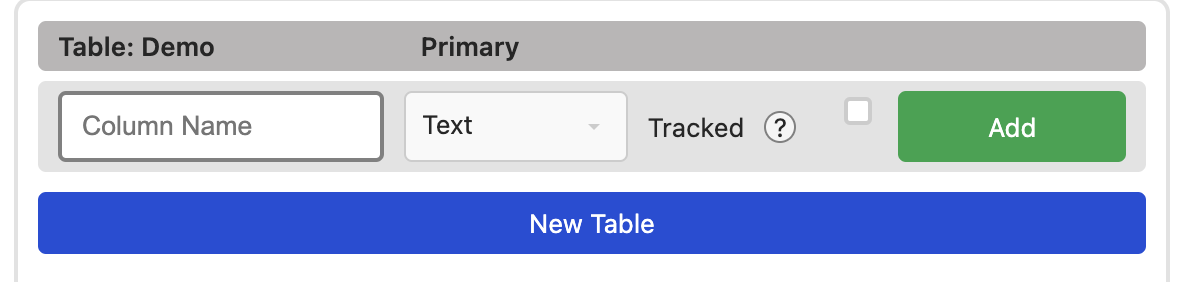
Die drei Optionen sind:
- Name der neuen Spalte
- Datentyp der Spalte
- Tracked: Checkbox, ob die Veränderung von Daten getrackt werden sollen. TODO: Aktuell wird dies nur im dem Server Log ausgegeben. Andere (nutzbare) Output Formate werden folgen
Ein Klick auf Add fügt die Spalte der Tabelle hinzu
Table/Column Enternen
Tabellen und Spalten können natürlich auch wieder entfernt werden. Dazu einfach auf das rote "X" neben der Spalte, oder dem Table Eintrag klicken. Dies entfernt natürlich auch alle bereits gecrawlten Werte.
Indexes
TODO:
Node Konfiguration
Annotations
Knowledge
TODO: Interface, um Wissen zu definieren
Page
Im Page Tab, lassen sich Konfigurationen zu allen verbleibenden Details der Seite vornehmen.
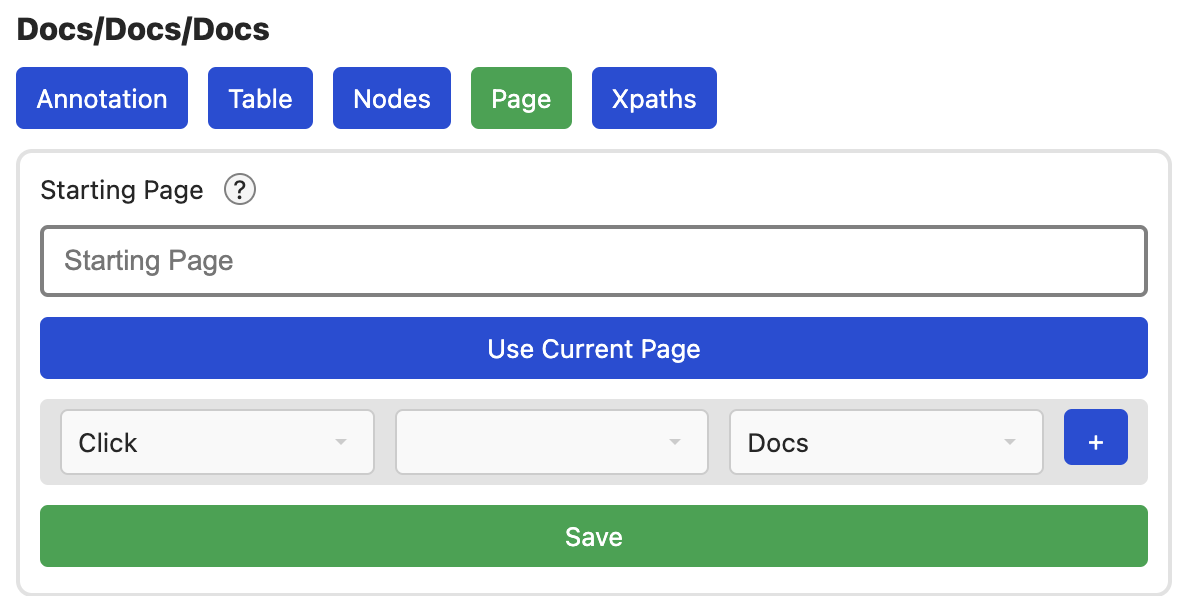
Starting Page
Zum Crawling benötigt es mindestens eine Seite, bei der das Crawling beginnen
soll. Diese Seite wird hier festgelegt. Dazu einfach auf den Use Current Page
Knopf drücken. Wichtig, diese Eigenschaft wird NICHT automatisch gespeichert,
sondern erst nach dem klicken von Save. Diese URL kann vorher bei Bedarf noch
angepasst werden.
Besonders interessant ist das ersetzen von Werten mit vorgegebenen Wissen. Bei einer URL wie
https://www.immobilien.de/results?postleitzahl=28215
lässt sich z.B. die Postleitzahl folgendermaßen ersetzen:
https://www.immobilien.de/results?postleitzahl={Postleitzahl}
Der Begriff in den {} Klammern wird in der Wissensbasis gesucht und durch
alle vorhandenen Werte ersetzt. Wenn man z.B. für Postleitzahl = [28217, 28219]
definiert hat, würde das Crawling mit allen folgenden URLs beginnen.
https://www.immobilien.de/results?postleitzahl=28217
https://www.immobilien.de/results?postleitzahl=28219
Auch komplexere replacements sind möglich, so können wir z.B. mit der URL
https://www.immobilien.de/results?postleitzahl={Postleitzahl}&typ={ImmobilienTyp}
und ImmobilienTyp = [Haus, Wohnung] alle folgenden URLs crawlen:
https://www.immobilien.de/results?postleitzahl=28217&typ=Haus
https://www.immobilien.de/results?postleitzahl=28217&typ=Wohnung
https://www.immobilien.de/results?postleitzahl=28219&typ=Haus
https://www.immobilien.de/results?postleitzahl=28219&typ=Wohnung
INFO: Das ganze funktioniert bereits ist aber wirklich erst zu nutzen, wenn
der Knowledge tab implementiert ist
Interaktionen
Manche Seiten benötigen bestimmte Interaktionen, um richtig zu funktionieren, oder um Suchergebnisse anzuzeigen. Dazu lassen sich um unteren Abschnitt Interaktionen definieren, die gemacht werden sollen.
Wichtig ist, dass eine Seite mit Interaktionen immer von Browser gecrawlt werden muss. Dies ist langsamer als das crawling von statischen Seiten, was vom Server schnellerer Internet-Verbingung und parallel erfolgen kann.
Die folgenden Interaktionen sind gegeben:
- Click: Klickt auf den Knopf mit der gewünschten Annotation. Da das
Klicken von Knöpfen oft die Seite wechselt, muss zusätzlich angegeben werden,
zu welcher Seite diese Interaktion führt. Eine sinvolle Konfiguration auf
einer Startseite wäre z.B.
Annotation: 'ErgebnisseAnzeigenKnopf', Page: 'Ergebnisse' - Input: Schreibt den gewünschten Text in das Input Element mit der
selektierten Annotation. Interessant wird dies hauptsächlich wieder mit
Ersetzungen. Diese laufen genau wie bei der Url.
{Postleitzahl}würde also alle Postleitzahlen eingeben. Dies passiert natürlich nicht gleichzeitig, sondern nacheinander, sobald das Crawlen der ersten Postleitzahl abgeschlossen wurde. - Scroll To End: Versucht einfach nur zum Ende der Seite zu scrollen. Dies kann bei Seiten wichtig sein, die sonst nicht alle Elemente anzeigen.
- Send Current: Sendet den aktuellen stand der Webseite zum Server zum
Auswerten. Dies passiert automatisch, wenn ein Click navigiert, oder das Ende
der Interaktionen erreicht ist. Für dynamische Seiten, dessen Stand man z.B.
vor und nach einem
Inputauswärten möchte, kann es allerdings sinnvoll sein, diese Option zu nutzten.
Ein Klick auf das + fügt die Interaktion hinzu. Bestehende Interaktionen
lassen sich mit X entfernen
Zum Schluss muss der aktuelle Stand mit Save gespeichert werden.
Xpaths
Der Xpaths Tab zeigt alle Xpaths der aktuellen Seite an. Xpaths geben an, wie das HTML DOM navigiert werden muss, um die Daten wirklich zu extrahieren.
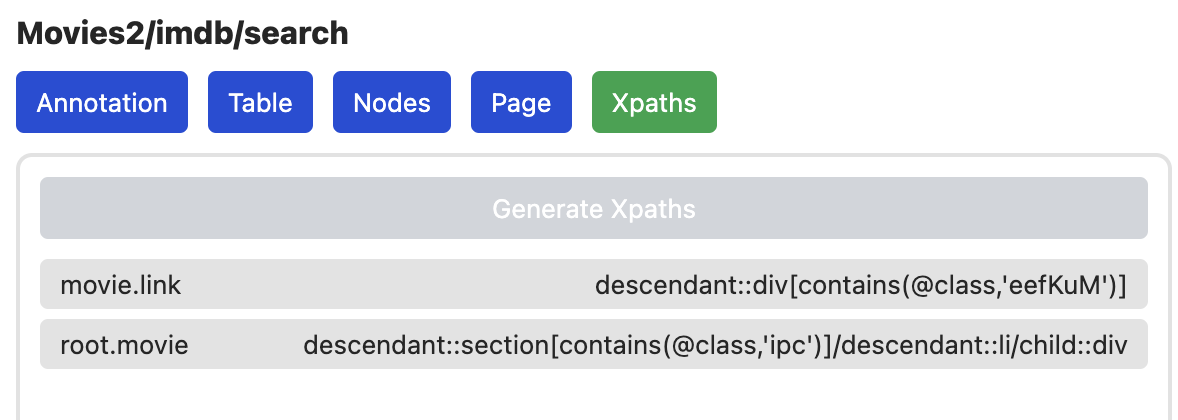
Ein Klick auf Generate Xpaths sendet die aktuell annotierte Seite an den
Server und aktuallisiert die Liste nach dem Abschluss mit den neuen Werten.
Bei Bedarf können auch Parameter der XPath Generierung angepasst werden. Diese Einstellungen sind:
- K: Die Menge an Xpaths, die Generiert werden. Dies beeinflusst ebenfalls die Qualität der Xpaths
- Complex XPaths: Erzeugt Xpaths, die rekursiv andere Xpaths enthalten. Ein
Beispiel wäre:
descendant::div[descendant::h1]
Beise Einstellungen beeinflussen nicht nur die Qualität, sondern auch die Dauer der Generierung.
Xpaths auswählen
In manchen Fällen kann es dazu kommen, dass der am besten bewertete XPath zu spezifisch ist, also z.B. den gesuchten Titel eines Films enthällt:
descendant::h1::[text()='Mission Impossible'] // Das Element mit genau diesem Text
oder sich zu sehr auf die absolute Position des Elements bezieht:
descendant::li[8] // Das 8. Listen element auf der Seite
Um sich manuell den besten XPath auszuwählen, kann man in der Liste der
generierten XPaths mit dem Set Knopf einen Xpath auswählen, der besser
funktioniert. Dieser wird daraufhin an die erste Stelle gesetzt.
Beispiel IMDB (Automatic)
Im folgenden werden wir die besten Filme von IMDB crawlen. Die URL dazu ist
https://www.imdb.com/chart/top/
und sollte zu Beginn geöffnet werden.
Zudem wird eine zunächst leeren Konfiguration und Datenbank angenommen. Meine Konfiguration dazu ist:
Project: Cinema
Site: IMDB
Page: Search
Die Such-Seite
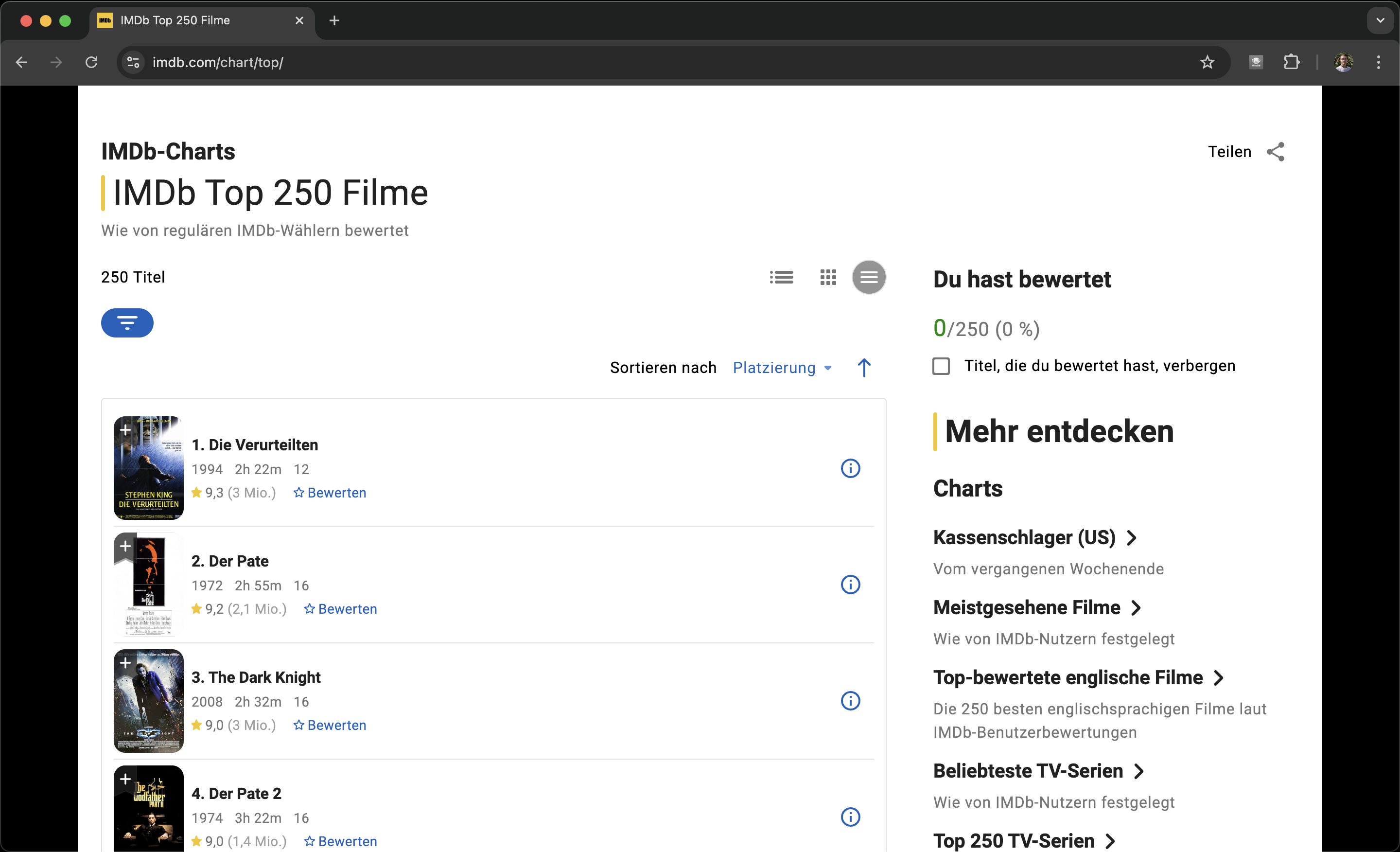
Unser Ziel auf dieser Seite ist es primär nur die URLs zu extrahieren. Dies benötigt im wesentlichen zwei Schritte. Movies selektieren & URLs extrahieren
Filme selektieren
Um alle Knoten zu selektieren, wählen wir im Annotations-Tab folgender Einstellungen:
- Annotation Name:
Movie - Annotation Count:
Simple ListDa wir mehre Elemente annotieren wollen - Action:
Create NodeErstellt automatisch eine neue Tabelle & Node mit dem Annotations Namen
Wir klicken auf Annotate und wählen nun die Movies so aus, dass sich die
Annotationen den gesamten Movie umfassen.

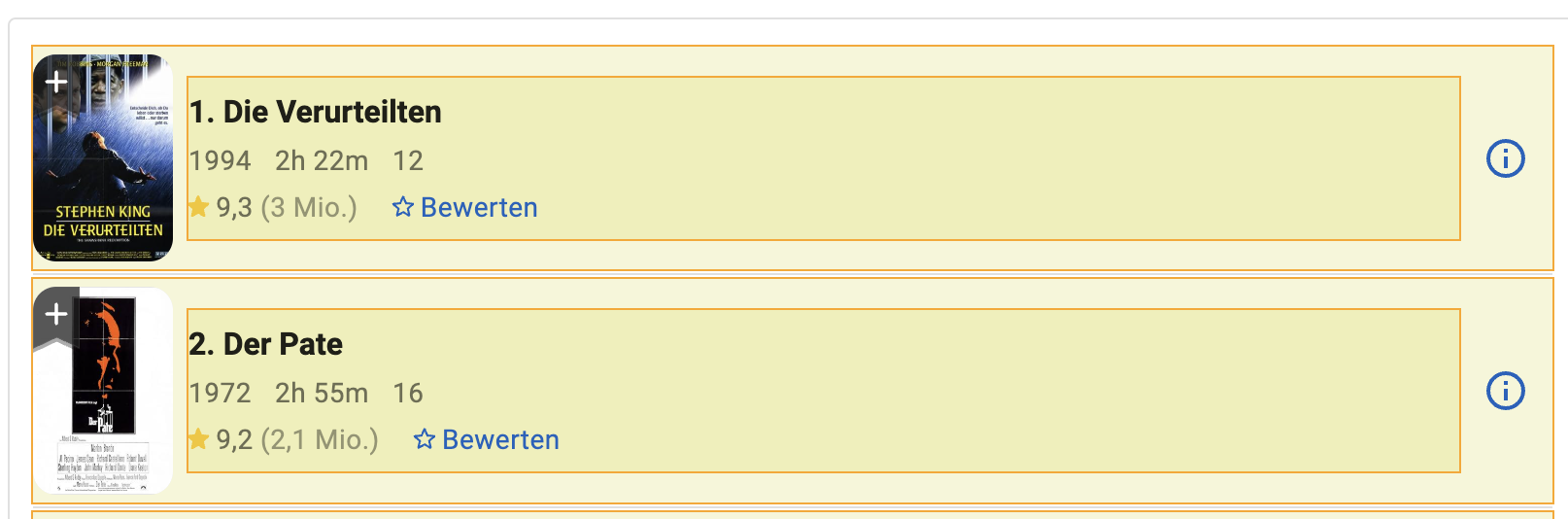
URLs extrahieren
Um URLs zu extrahieren ist vollgende Konfiguration sinnvoll:
- Annotation Name:
MovieLink - Annotation Count:
Simple ListDa wir die Links aller Movies wollen - Action:
Create Data PointStellt sicher, dass der Link dem Movie zugeordnet wird - Data Target:
LinkExtrahiert den ersten Link, der im selektierten Element gefunden wird. Erzeugt zudem eine fetch_url Zeile für Movie, markiert diese URL zum Crawlen der Movie Seite und erzeugt eine neue Seite "Movie", die bereits auf die Movie Tabelle konfiguriert ist
Eine grobe Auswahl des Bereichs, in dem der Link ist reicht aus
Page Config
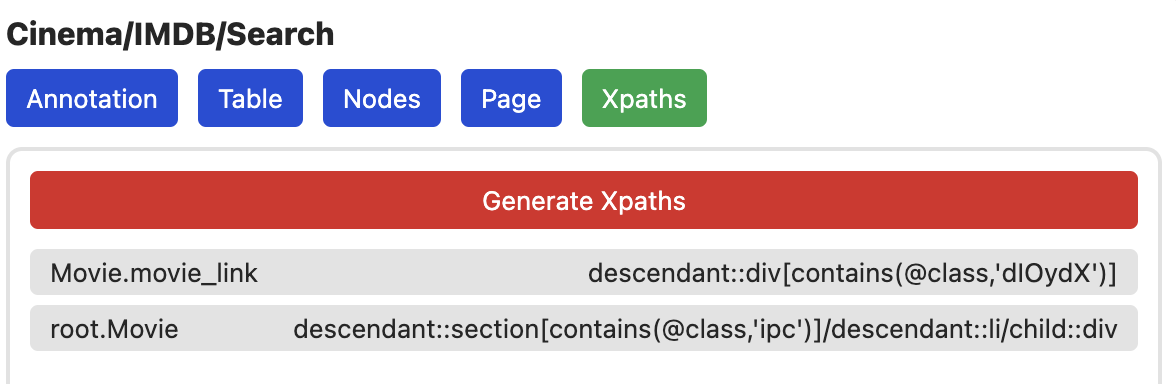
Damit wir die Seite auch korrekt crawlen, müssen wir zunächst XPaths generieren. Dazu zum XPath Tab wechseln und den Knopf drücken. Nach ein paar Sekunden, sollte das Ergebnis so aussehen:
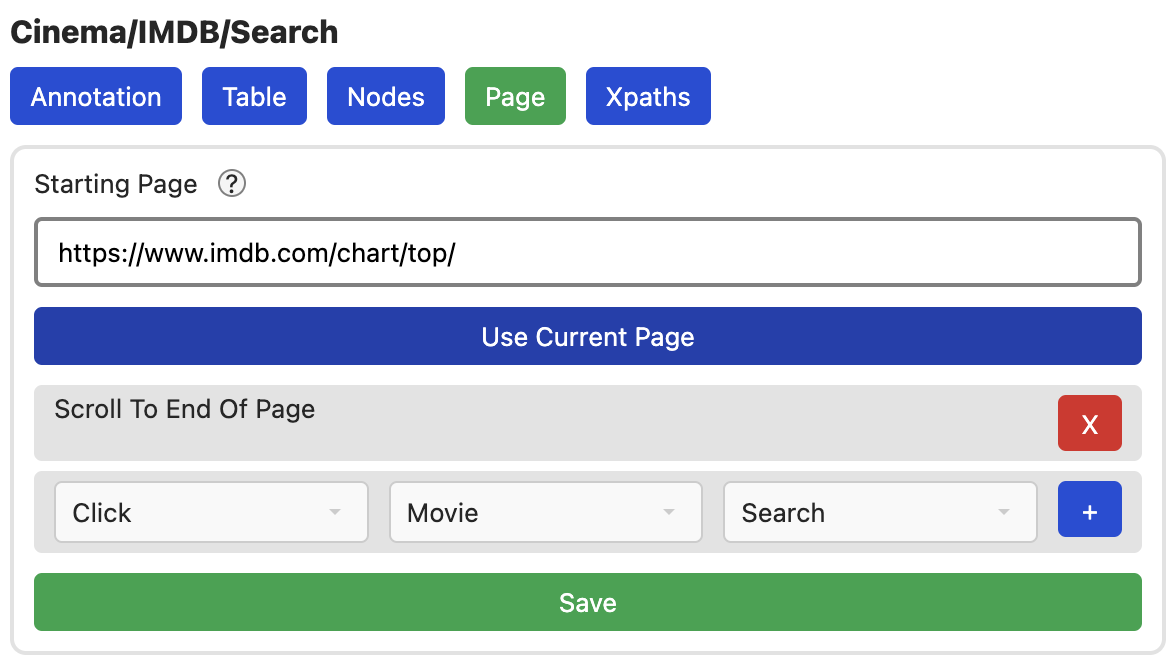
Da wir uns auf der Startseite befinden, müssen wir diese Seite auch als Crawling-Startseite festlegen. Um sicher zu stellen, dass alle Elemente geladen werden, wollen wir zudem, dass dies Seite im Browser geöffnet wird und nach unten gescrollt wird.
Das ganze sollte nun so ausssehen:
Nun nur noch speichern und diese Seite ist abgeschlossen.
Test
Zum Testen, könnnen bereits das Crawling starten und uns das Ergebnis über die DB Overview anschauen:
Die Film-Seite (Details)
Mit der Konfigurtion der IMDB-Suche abgeschlossen, können wir nun zur Detail-Seite wechseln. Dazu einfach auf einen der Filme klicken und im Erweiterungs Popup-Menü die neue Movie Seite auswählen. Diese wurde erstellt, als wir in den Movie node einen Link selektiert haben.
Movie Infos
Da diese Seite bereits auf die Movie Tabelle verweist, können wir einfach simple Punkte hinzufügen, die wir extrahieren wollen. Die default Annotations-Konfiguration ist dafür bereits korrekt, wir müssen nur einen Namen und ggf. Datentyp festlegen:
- Annotation Name:
Title - Annotation Count:
Single ElementDa wir nur ein simples Element extrahieren wollen - Action:
Auto PointErstellt automatisch eine neue Spalte in der Movies Tabelle - Data Target:
Table Insert - Insertion Type:
Text
Danach annotieren wir einfach das gewünschte Element
Das gleiche können wir für alle weiteren Elemente wiederholen:
- Annotation Name:
Description - Annotation Count:
Single ElementDa wir nur ein simples Element extrahieren wollen - Action:
Auto PointErstellt automatisch eine neue Spalte in der Movies Tabelle - Data Target:
Table Insert - Insertion Type:
Text

Test
Auch hier, können wir direkt testen, ob unsere Konfiguration funktioniert. Dazu zunächst Xpaths generieren.

Da wir das Crawling nicht auf dieser Seite beginnen wollen und auch keine Interaktionen brauchen, können wir einfach das crawling starten. Schauen wir uns nach ein paar Sekunden das Resultat in der Datenbank an, sehen wir die neuen Felder gefüllt mit Daten
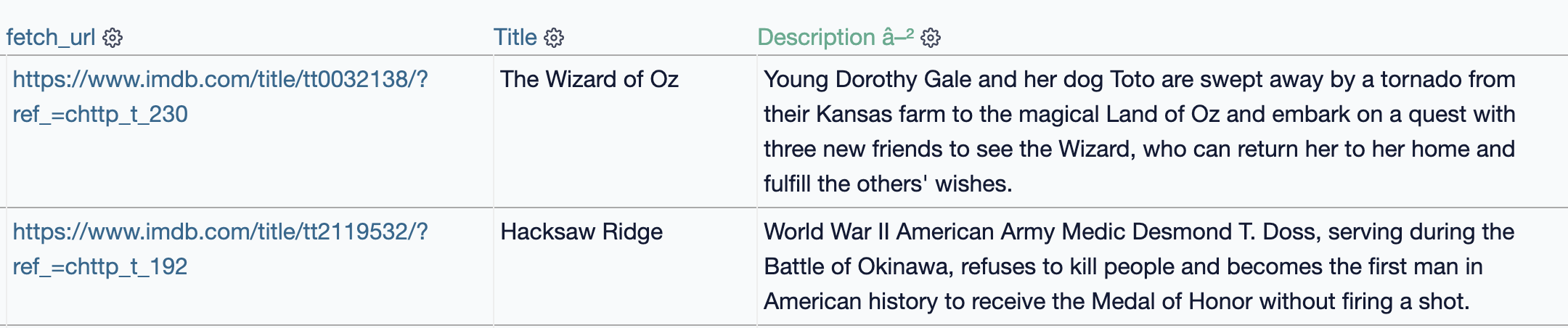
Die Film-Seite (Schauspieler)
Wir wollen neben den normalen Details zum Film ggf. auch Listen von Informationen crawlen. Dazu wählen wir mit den selben Einstellungen wie auf der Such-Seite einfach die Knoten aus:
- Annotation Name:
Actor - Annotation Count:
Simple ListDa wir mehre Elemente annotieren wollen - Action:
Create NodeErstellt automatisch eine neue Tabelle & Node mit dem Annotations Namen - Node Table:
AutoErstellt eine Actor Tabelle - MtM Table:
AutoErstellt eine Actor2Movie Tabelle, die automatisch geupdated wird

Node Ident
Bei der Such-Seite haben wir als "Primary Key" für die Suchergebnisse die URLs genommen. Das Selbe könnten wir jetzt auch tun. Zur Abwechslung werden wir jetzt allerdings einfach den Namen nehmen. Dazu nehmen wir folgende Einstellungen:
- Annotation Name:
Name - Annotation Count:
Simple ListDa wir die Namen aller Schauspieler wollen - Action:
Auto PointStellt sicher, dass der Name dem Actor zugeordnet wird - Data Target:
IdentErstellt eine neue Spalte in der Actor Tabelle und setzt diese als Ident ~(Primary Key)

Test
Zum Testen müssen wir wieder XPaths generieren.

Und können danach das Crawling starten. Wir sehen eine neue Actor Tabelle mit allen einzigartigen Actors.
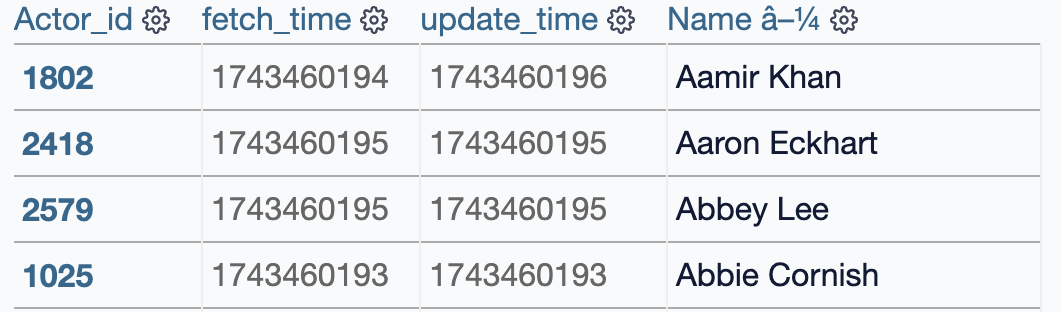
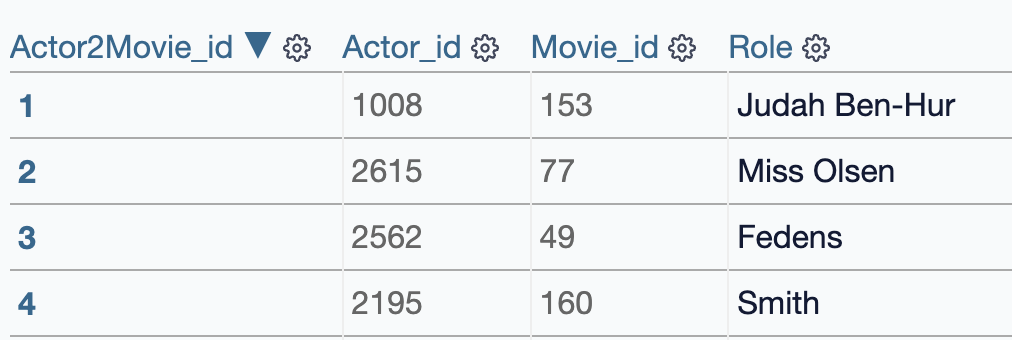
Zudem sehen wir eine Actor2Movie Tabelle, in der die Beziehungen zwischen Actor und Movie gespeichert sind:

Rolle
Ggf. ist uns das noch nicht genug. Wenn wir auch noch extra Daten, z.b. die Rolle des Schauspielers in die Tabelle schreiben wollen. Dazu wählen wir die Einstellungen wie bei einem normalen Punkt, nur dass wir MtM Insert als Data Target wählen:
- Annotation Name:
Role - Annotation Count:
Simple ListDa wir mehre Elemente annotieren wollen - Action:
Create Data Point - Data Target:
MtM InsertDa wir in die MtM Tabelle zwischen Actor und movie schreiben wollen
Wir annotieren nun die Rolle:
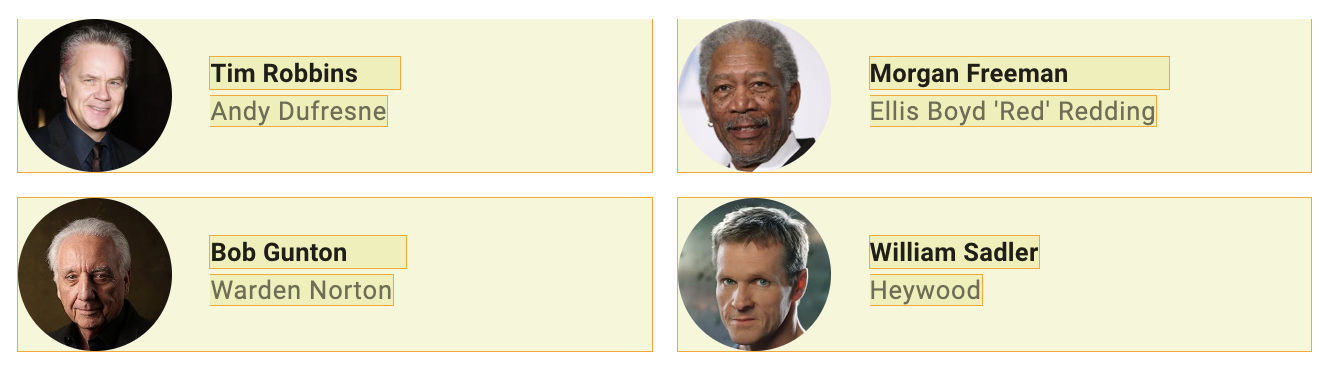
Test
Wir generieren wieder Xpaths, starten das Crawling und schauen uns die Tabelle an:
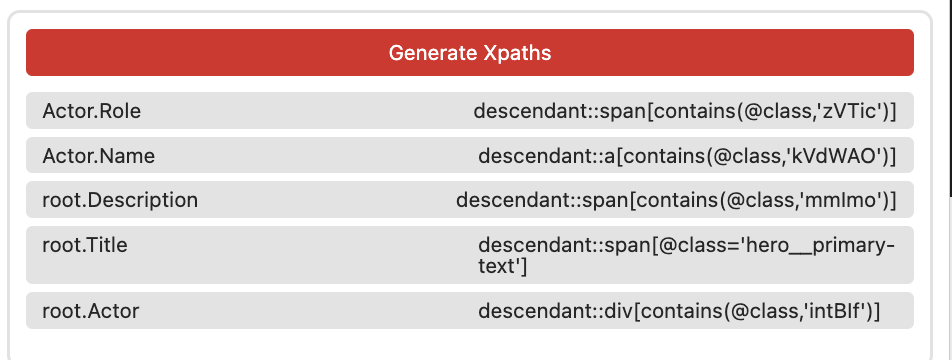
Ein Blick in die Datenbank zeigt, dass die neue Spalte korrekt mit Daten gefüllt wurde.
Dynamische Seiten (Interaktionen & Knowledge)
Wenn man ein größeres Datenset auswerten möchte, wird man mit den 250 Top Filmen vermutlich nicht weit kommen. Wir schauen uns also stattdessen nun die erweitere Suche von IMDB an:
https://www.imdb.com/de/search/title/
Da es sich hier um eine neue Seite handelt, erstellen wir dafür zunächst eine
neue Page im Popup der Erweiterung. In diesem Fall mit dem kreativen Namen
AdvancedSearch:
// TODO: Bild
Voreinstellungen
Bei der Menge an Filmen auf IMDB ergibt es Sinn, nur relevante einträge zu
crawlen. Dazu wählen wir in den Einstellungen links aus, dass wir nur Filme mit
mindestens 100.000 Bewertungen sehen wollen. Wir klick auf
Ergebnisse Anzeigen, die Url ändert sich zu
https://www.imdb.com/de/search/title/?title_type=feature&num_votes=100000, und
wir sehen nun die Ergebnisse.
// TODO: Bild
Buttons
Auf dieser und einigen anderen Seiten ist es erforderlich mit der Seite zu
interagieren, statt nur Werte zu extrahieren. Zuvor hat uns dazu die
Scroll To End Interaktion gereicht. Bei der erweiterten Suche handelt es
sich allerdings um eine manuelle Variation des "Infinite Scrolling" Mechanismus,
bei der man immer wieder 50 mehr anklicken muss, um alle ergebnisse zu
extrahieren. Genau das wollen wir nun automatisieren. Dazu annotieren wir
zunächst den entsprechenden Knopf auf der Webseite mit der einfachsten
Annotations Variante:
- Annotation Name:
More - Annotation Count:
Single Element - Action:
Only AnnotationErstellt nur eine Annotation
Wir klicken auf Annotate und wählen nun den Button so aus, dass das gesamte
klickbare Element ausgewählt ist.
// TODO: Bild
Interaktionen
Wir wechseln in den Page tab und klicken genau wie auf der ursprünglichen
Such-Seite auf Use Current Page. Daraufhin geht es an die Interaktionen. Da der
Knopf such am Ende der Seite befindet, ergibt es sinn zunächst wieder mit einem
Scroll To End zum Ende der Seite zu navigieren. Wir wählen diesen Typ also
aus und klicken auf +.
Daraufhin wählen wir Click aus, was uns zwei Felder zum auswählen gibt. Das
Erste davon ist für die Annotation, also das Element, das wir anklicken wollen.
Das Zweite ist die Seite, zu der wir wechseln, wenn wir auf den Knopf drücken.
Dies kann nütlich sein, um z.B. von einer Suche (Text input) zu einer anderen
(Results) zu wechseln. Da wir hier allerdings auf der selben Seite bleiben,
wählen wir die aktuelle.
Wir wählen also:
- More Um den annotierten
50 MehrButton zu klicken - AdvancedSearch Um auf der selben Seite zu bleiben.
und klicken daraufhin auf Save.
Test
Wir können nun bereits testen, ob unsere Konfiguration funktioniert. Dazu einfach wieder XPaths generieren. Und das crawling starten. Wenn die Top250 Seite noch konfiguriert ist, sollten beide Seiten nun nacheinander gecrawlt werden, wobei die AdvancedSearch immer weiter nach unten scrollt.
Da wir noch keine anderen Elemente auf dieser Seite selektiert haben, finden wir allerdings keine neuen Einträge in der Datenbank
Filme
Um die Filme wie zuvor wirklich zu crawlen, müssen wir erneut die selben Schritte, wie bei der Top250 Seite durchlaufen. Im Schnelldurchlauf:
Die Film-Knoten annotieren mit den folgenden Werten:
- Annotation Name:
Movie - Annotation Count:
Simple ListDa wir mehre Elemente annotieren wollen - Action:
Create NodeErstellt automatisch eine neue Tabelle & Node mit dem Annotations Namen
Wir klicken auf Annotate und wählen nun die Movies wieder so aus, dass sich die
Annotationen den gesamten Movie umfassen.
Urls extrahieren
Um Urls zu extrahieren ist vollgende Konfiguration sinnvoll:
- Annotation Name:
MovieLink - Annotation Count:
Simple ListDa wir die Links aller Movies wollen - Action:
Create Data PointStellt sicher, dass der Link dem Movie zugeordnet wird - Data Target:
LinkExtrahiert den ersten Link, der im selektierten Element gefunden wird
Eine grobe Auswahl des Bereichs, in dem der Link ist reicht aus
Test
Auch hier können wir nun wieder XPaths generieren und das crawling starten. Dieses Mal werden neue Ergebnisse in der Datenbank auftauchen.
// TODO: Bild
Segmentiertes crawling
Die Ergebnis-Seite kann schnell sehr groß werden. Bei 2000+ Ergebnisse mit Bildern, Links, Text und ggf. Werbung, kann eine einzige so durchlaufene Webseite oft mehre Gigabyte an Arbeitsspeicher und ähnlich viel CPU Leistung kosten, um korrekt dargestellt zu werden. Wenn der Browser dadurch hängt, kann dies zu Fehlern führen (Next Button wird nicht angezeigt, Browser stürzt ab, etc.).
Wir sehen, dass unsere aktuelle URL die Anzahl der Votes als Parameter enthällt. Zum Testen, ändern wir auf der IMDB Seite die Einstellungen, um auch eine Obergrenze hinzu zu fügen die URL wird:
https://www.imdb.com/de/search/title/?title_type=feature&num_votes=100000,2147483647
Wir können also die IMDB Suche über die Menge an Votes Segmentieren. Also zum Beispiel immer in 100er Schritten. Dies können wir manuell machen, indem wir zwischen Crawling-Durchläufen immer wieder die URL im Page tab verändern.
Diese Arbeit können wir allerdings auch automatisieren. Dazu wechseln wir in den
Knowledge Tab. Dort fügen wir eine neuen Eintrag mit dem Namen range hinzu
und klicken auf Add.
// TODO: Range definieren und URL ersetzen